目标检测(one stage)-YOLOv2
一. 与V1的不同之处
YOLOv2相较于YOLOv1在VOC2007数据集上表现从63.4%提升到78.6%。

YOLOv2与YOLOv1的不同之处一共体现在下面几个方面:
-
Batch Normalization(批归一化层):在模型不过拟合的前提下,可以拿掉Dropout层;同时加速模型训练。在VOC2007数据集上效果mAP提升2.4%。
-
High Resolution Classifier(提高分辨率):原本YOLOv1中模型训练的使用的是224 * 224分辨率的图像,现在resize成448 * 448的图片,最后经过10个epoch的微调。在VOC2007数据集上效果mAP提升3.7%。
-
Convolutional With Anchor Boxes(提高检测目标数量):原本yolov1中将其中一个pool层拿掉后, feature map的大小由7 * 7 变成了13 * 13,然后每个1 * 1的grid里面增加了K个anchor boxes,因此从yolov1只能检测7 * 7 = 49个目标,增加到了13 * 13 * K个目标。在VOC2007数据集上效果虽然mAP下降了0.3%,但是在Recall上提升了7%。
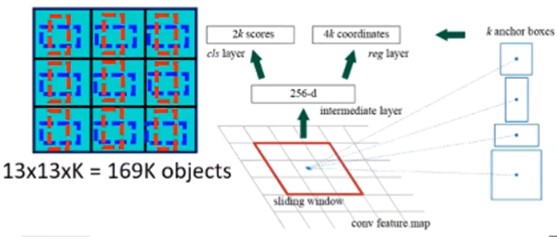
-
New Network(DarkNet-19):提出了一个新的网络架构DarkNet-19(19个Conv 和 5个MaxPool),能够在YOLOv1的基础上减少33%的计算量。在VOC2007数据集上效果mAP提升0.4%。
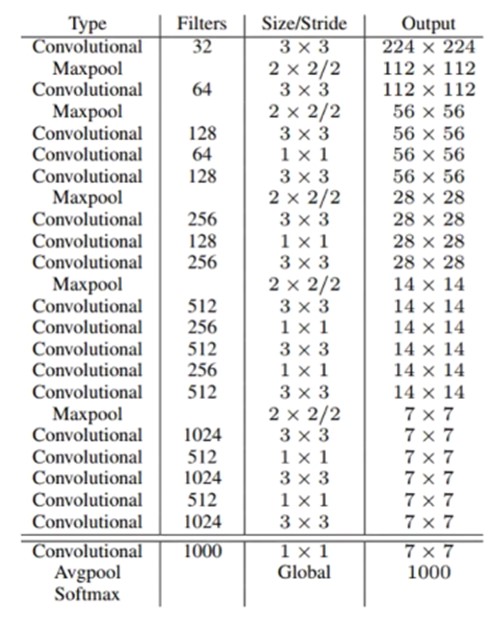
-
Dimension Clusters(尺度聚类):如果Anchor boxes一开始就能和实际的物体的宽高比很接近,那么对于模型的收敛是否有帮助呢?YOLOv2这里就是使用了KMeans对所有的图片的宽高比(利用IOU计算之间的距离)进行聚类,结果是聚类个数K取5效果最好,从而每个grid中找到5个最好的预选框。
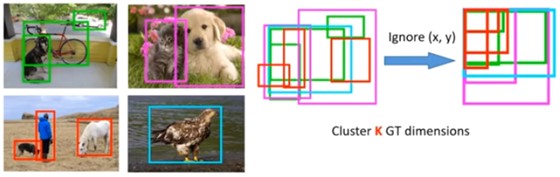
-
Direct Location Prediction(绝对位置预测):模型原本的anchor box在预测物体的x,y坐标时候会发生数值不稳定的现象(而R-CNN网络的boundingbox并非随机,而是由RPN网络生成),毕竟随机初始化的anchor box的位置,肯定需要花费大量时间才能学习到合适的位置。那么yolov2是如何完成?这里红色为anchor box,蓝色为模型的预测框,这里引入sigmoid函数来缩小到(0,1)之间,同时对计算后的结果进行归一化的处理,
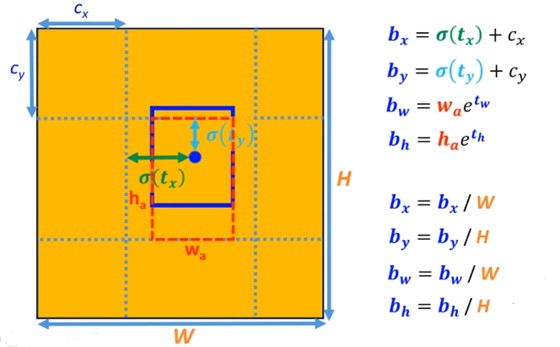
使用尺度聚类和直接位置预测两种方式后模型在VOC2007数据集上效果mAP提升4.8%。
-
Fine-Grained Features(颗粒度特征):将feature map拆解成更小的feature map。借由前面DarkNet得到高解析度的特征拆解成小解析度的特征,因此来检测较小的物体。VOC2007数据集上效果mAP提升1%。
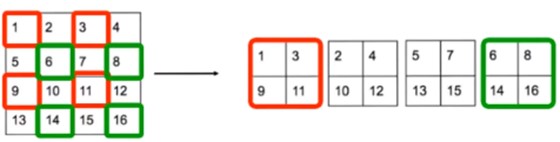
-
Muti-Scale Training(多尺度训练):每10个batch去做一个resize的动作,从一开始的320 * 320到最终的608 * 608,最后得到的feature map从开始的10 * 10到19 * 19。VOC2007数据集上效果mAP提升1.2%。
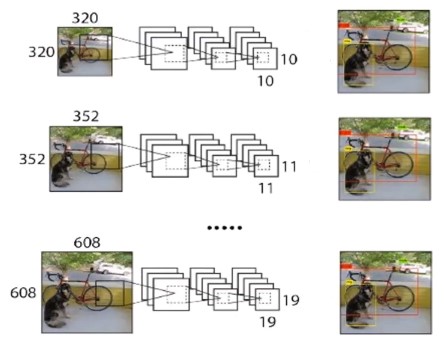
-
High Resolution Detector(输入大size的input):通过输入图像尺寸更大,使得模型检测到更小物体。下图是从288到544尺寸之间mAP提升效果,当然fps会相应的减少。VOC2007数据集上效果mAP提升2%。
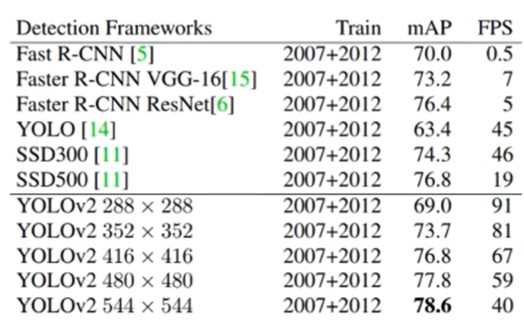
二. 其他模型的比较
下图是YOLOv2在COCO2015数据集上的表现。
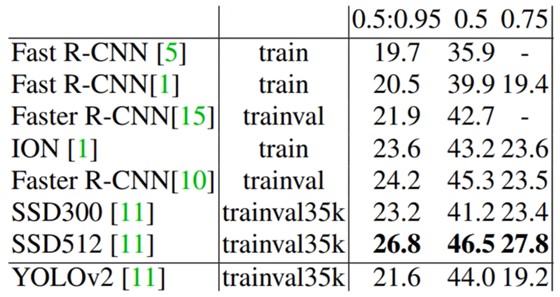
可以看到YOLOv2相较于SSD还有一些的差距的。