目标检测(one stage)-SSD
一. YOLO和SSD的对比
yolo和ssd两个模型结构如下图所示:
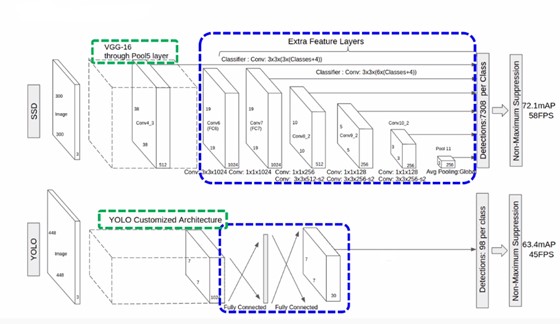
两个模型之间最主要的差别:
- 在特征抽取层其实相差不大:YOLO用的是器自己的conv架构;SSD用的是VGG-16
- 主要差别在结果预测上:YOLO用的是全连接层后得到7*7的grid,利用每个grid的boundingbox来做目标检测;SSD利用不同大小的feature map来做目标检测。
二. 模型结构
2.1 特征抽取层
那么如何从VGG-16的结构变成SSD的结构呢?下图是一个VGG-16的示意图。

将VGG-16的最后一层pooling层变成3*3 的卷积层,再接一个atrous conv(空洞卷积)拿到不同大小的feature map。如下所示。
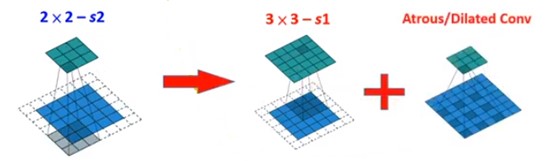
2.2 空洞卷积
这里运用atrous conv layer而不是普通的conv layer的目的:
- 在相同的感受野的同时,能获得更快的运算速度
如下图所示,是5 * 5 的卷积的kernel和3 * 3的atrous conv的kernel的感受野。
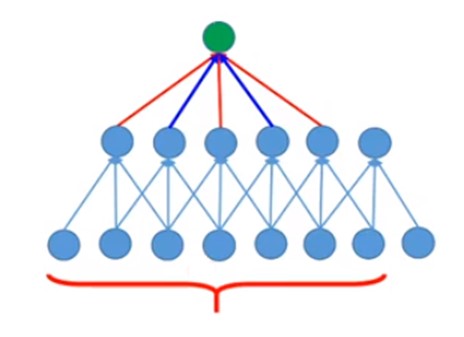
可以看到,如果是3 * 3的conv层接5 * 5的conv层,那么feature map中单一点的感受野其实是7个像素点;而如果是3 * 3的conv层接3 * 3的atrous conv层,能达到相同的感受野,且计算速度更快。
2.2 推理层
下图是SSD的推理层的示意图。
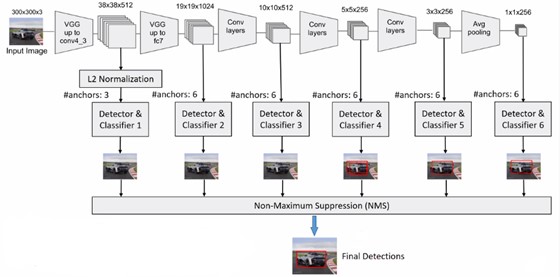
可以看到,图片经过vgg16之后,首先会得到较浅的feature map,随后经过几层卷积之后,得到较为深层的feature map(所以在上图中仅有较深层的能检测到车这种大物体),同时每层的feature map都会经过一个检测器和分类器得到检测结果,最后经过NMS得到最终的检测结果。
那么整个SSD的anchor box的数量是: \(38*38*3+19*19*6+10*10*6+5*5*6+3*3*6+1*1*6 = 7308\)
三. 模型训练
3.1训练loss
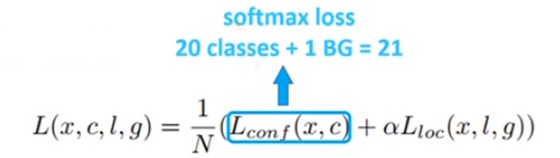
SSD和YOLO的loss中的检测类别值有所不同:假定检测目标一共A个类别,那么YOLO的预测类别数位A个,而SSD的预测类别则是A+1个(包含了背景类)。如下图所示。
3.2 难负例挖掘
对于正负样本不均衡的情况,SSD采用了hard negative mining(难负例挖掘)技巧来解决。hard negative是指在图片中容易将负样本(背景)看成是正样本(前景)的样本。而mining的操作就是将这类样本放入模型进行学习,从而减少模型的false positive。
那么SSD是如何引用hard negative mining技巧呢?如下图,其中蓝色的box的我们希望它的confidence较低,而绿色的confidence较高。
- 对于一张图而言,选出其中anchor box中negative置信度较高的box。
- 正负比例的anchor box = 1:3

3.2 数据增强
SSD模型在论文中也使用了很多不同的data augmentation(数据增强)的操作。
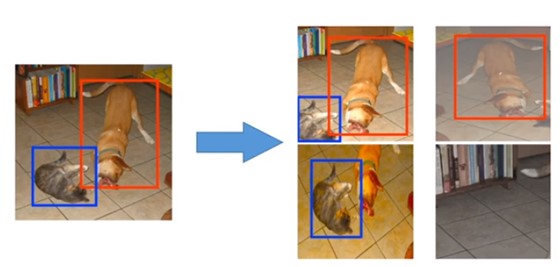
方式一:
- 针对原始输入图片和ground truth进行IOU的操作
- 对其中iou = 0.1,0.3,0.5,0.7和0.9来进行采样。
- 对采样后的图片进行resize成相同大小的图片,然后进行水平翻转的操作。
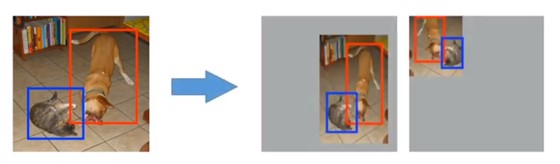
方式二(Random Expansion-得到的小目标训练样本):
- 对原始图像做不同比例的缩小。
- 然后放在相同大小图片中不同的地方。
四. 结果比较
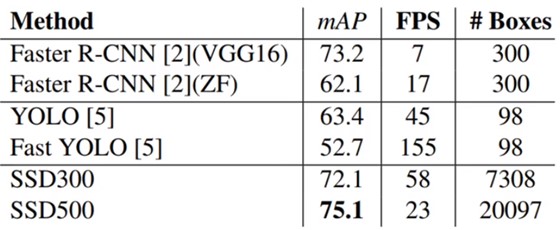
可以看到,SSD相较于YOLO在准确性上有很大的提升,同时预测速度上也能达到很高的fps。