目标检测(one stage)-从FPN到DSSD
一. FPN特征金字塔网络
论文地址:https://arxiv.org/pdf/1612.03144.pdf
这篇论文发布的时间是2017年4月19号,可以说在此之后,对于目标检测(小物体)而言,提升巨大,基本之后的模型比如DSSD,yolov3等都参考过该模型架构。
1.1 解决的问题
- 目标检测的基本挑战(问题):识别多尺度变化的目标能力不足。这里解决了一下两个方面的难点:
- 相机距离目标远近不同导致拍摄的图片中目标尺寸不同而导致识别效率低下。
- 小目标物体的识别较难。
1.2 图像特征金字塔
特征金字塔是在不同大小尺寸的目标检测中的一个基础组件。
- 如下图所示,经过多次特征抽取后,越到高层的feature map所囊括的细节信息就越少,对于底层信息(比如小的目标)预测就越难。
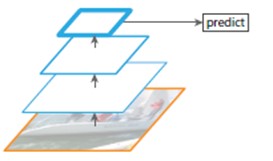
- 那么图像特征金字塔做了什么呢?既对同一张图片进行多次下采样,从而得到多张不同尺寸的图片,进而生成不同尺寸的feature map,从而使模型拥有对不同尺度大小的物体进行检测的能力。但是论文中也提出它的问题:消耗太大的内存和计算量。
-
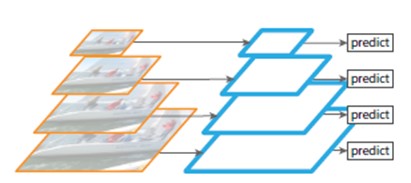
看到上面这张图的时候,你是不是觉得很熟悉?和某个网络的推理层很像?是的,就是SSD。SSD和YOLOv1最大的差别(之前的文章中有讲,有兴趣可以查看本人之前的文章)其实是推理层的不同,SSD用的就是多尺度的特征图综合来预测目标,从而达到对于小物体也能够检测的目的。
-
如下图所示,是不是感觉和上面的图像特征金字塔很像?差别还是有的,SSD是对同一张图片进行卷积抽取其不同尺度的feature map进行分别做预测,而特征金字塔是对不同尺度的图片分别做特征抽取得到不同尺度的feature map在分别做预测。这里论文中也提到SSD的缺点:失去了高层语义信息重用的机会,导致低层语义信息不足。
1.3 特征金字塔网络(FPN)
这里推荐一篇个人认为不错的git仓库:easy-fpn.pytorch,是由pytorch复现的fpn网络。
FPN的网络结构如下图所示:
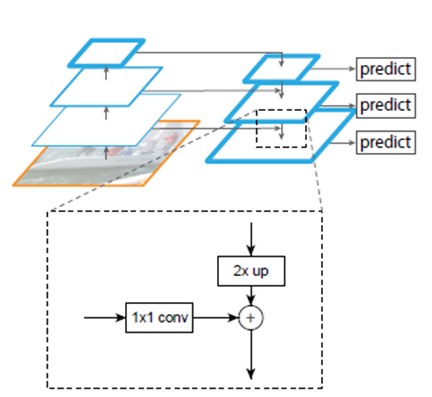
我们可以看到,其实说白了FPN相较于SSD和特征金字塔厉害的地方:
- 强于SSD:重用了高层语义信息,每次预测都是结合了当前层和上一层的语义信息,使每一层不同尺度的特征图都具有较强的语义信息。
- 强于特征金字塔:同样通过上下采样(这里不同的是采样的feature map),使模型拥有对不同尺度大小的物体进行检测的能力,却又构建了一个端到端的网络。
下面是来源于我上面推荐的git仓库的FPN网络的细节架构图。方便我们很好的理解FPN中到底做了什么。如下图所示,从底层的feature map(1067 * 800)到高层的feature map(34 * 25),每层feature map经过1 * 1的卷积之后和经过up sample之后的上层feature map做一个add操作,在进行推理。
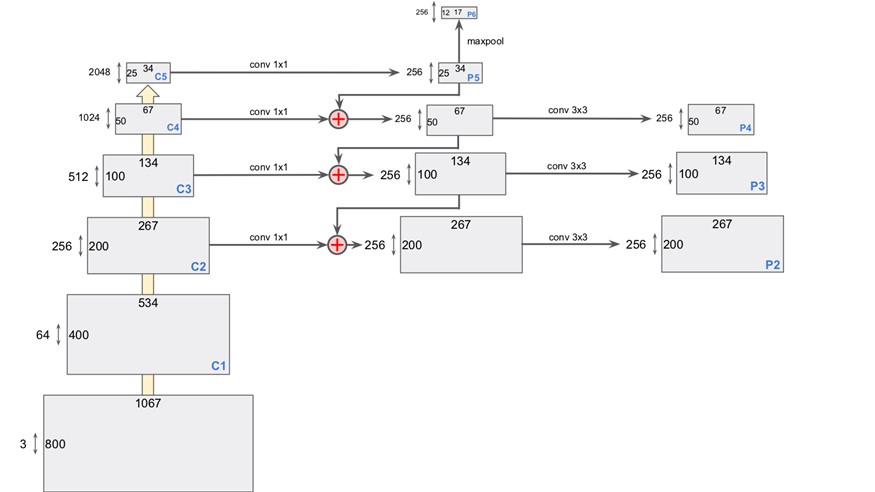
下面是细节复现的pytorch代码:
# Bottom-up pathway
c1 = self.conv1(image)
c2 = self.conv2(c1)
c3 = self.conv3(c2)
c4 = self.conv4(c3)
c5 = self.conv5(c4)
# Top-down pathway and lateral connections
p5 = self.lateral_c5(c5)
p4 = self.lateral_c4(c4) + F.interpolate(input=p5, size=(c4.shape[2], c4.shape[3]), mode='nearest')
p3 = self.lateral_c3(c3) + F.interpolate(input=p4, size=(c3.shape[2], c3.shape[3]), mode='nearest')
p2 = self.lateral_c2(c2) + F.interpolate(input=p3, size=(c2.shape[2], c2.shape[3]), mode='nearest')
# Reduce the aliasing effect
p4 = self.dealiasing_p4(p4)
p3 = self.dealiasing_p3(p3)
p2 = self.dealiasing_p2(p2)
p6 = F.max_pool2d(input=p5, kernel_size=2)
二. DSSD
论文地址:https://arxiv.org/abs/1701.06659.pdf
这篇论文发布的时间是2017年1月23号。DSSD(Deconvolutional Single Shot Detector),听名字就知道了,是SSD的升级版本,而且其实就是SSD + FPN的结合体,但是很奇怪,为啥你还在别人FPN后面发布呢?
2.1 和SSD的差别
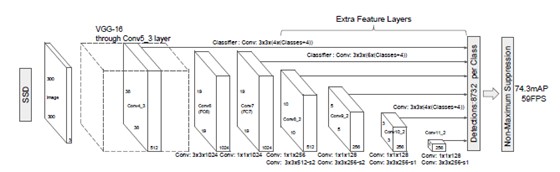
下图是SSD和DSSD的网络架构示意图。
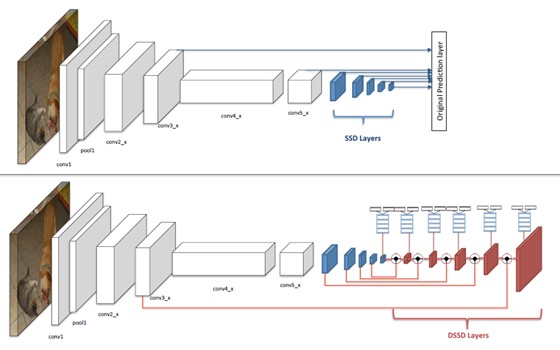
SSD和DSSD在前面特征抽取层的backbone都是一样的,差别在于后面推理的过程:
- SSD的推理过程经过多个卷积得到的不同尺寸的特征图来进行预测。
- DSSD的推理过程是FPN网络架构的复现:由底层特征结合经up sampling之后的上层特征,做一个结合的操作,论文中提到2中结合方式:
- Eltw-sum:也叫broadcast add,将浅层和深层的特征图在对应的通道上做加法运算。
- Eltw-prod:也叫broadcast mul,将浅层和深层的特征图在对应的信道上做乘法运算。
2.2 DSSD在模型效果上的提升
下图是SSD(左1和右1)和DSSD(左2和右2)的模型在同一张图片上的检测效果。

可以明显的发现:
- DSSD能检测到更多的目标。
- DSSD能检测到更小的目标。