大语言模型的应用及训练
一. 大语言模型LLM
1.1 LLM的发展史
LLM(Large Language Model大语言模型)的发展起源应该是从Transformer开始,在chatGPT出现后热度达到顶峰。

整个发展的过程可以概括为三个阶段:
-
第一阶段:真对某些领域数据单独微调,出现大量的预训练模型
-
第二阶段:扩大模型参数及训练语料的规模,模型架构偏向于生成式模型,Prompt在微调阶段开始展现。
-
第三阶段:模型参数和数据的规模急剧扩大,注重模型和人之间的交互。AI的安全性、可靠性更加收到关注。
1.2 开源可用的中文LLM
目前公认较好的中文开源大语言模型如下:
-
Meta AI发布的Llama系列模型,目前已经到Llama2了,推荐一个中文的Llama2仓库
-
清华大学的chatGLM系列模型,目前已经到chatGLM2了,推荐官方的chatGLM2仓库
1.3 LLM应用的NLP任务
现在LLM基本都是生成式模型,因此一般可应用的NLP任务:
-
翻译
-
文本摘要
-
阅读理解
-
知识问答
二. LLM的训练
大语言模型训练面临最大的挑战主要有以下2方面:
-
模型太大,一个GPU放不下
-
数据量太大,一个GPU训练时长太长
2.1 主流的训练加速方式
目前主流的LLM训练的加速方式有以下三种:
-
数据并行DataParallel:N个GPU上放置同一个模型(模型复制N份),将数据切分成N份。每台GPU都独立地执行前向计算过程(获得损失loss)和后向传播过程(计算梯度),之后对所有GPU上的梯度同步后进行参数更新(或直接同步更新后的参数)。
-
流水线并行PipelineParallal:N个GPU上放置一个模型的不同layer,同一份数据(数据复制N份)。每个GPU只负责其中一部分layer的训练,数据在不同卡上流转的时候,都需要自动将数据放到对应的卡上。
-
张量并行TensorParallel:可以理解为数据并行+流水线并行(强力推荐)。N个GPU上放置一个模型的不同layer,同时将数据切分成N份,即每个GPU上对应模型的一份layer和一份数据。
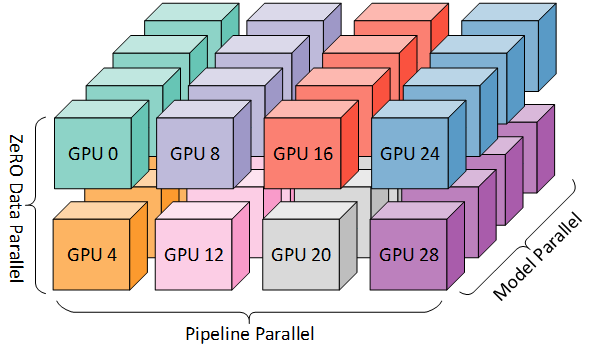
那么为什么要推荐使用张量并行的方式来进行加速呢?
无论是数据并行还是流水线并行,当模型足够大时,在前向和后向传播时,GPU之间的所需要传递的信息(包括模型的参数/梯度/优化器状态)就会很大,那么GPU之间通信所需的时间就会很长,而这段时间中其他的GPU其实是处于空置状态,很浪费资源。
2.2 DeepSpeed的ZeRO
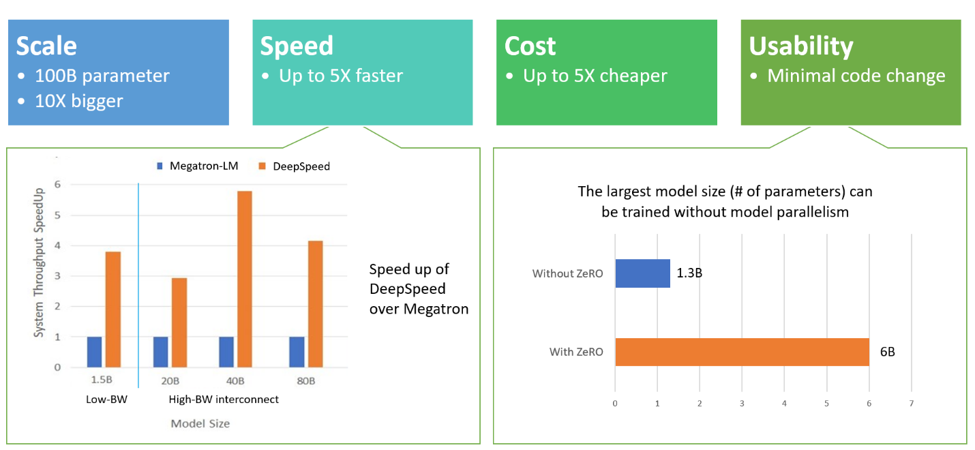
DeepSpeed是微软的分布式框架,而它的核心就是ZeRO(Zero Redundancy Optimizer),《ZeRO: Memory Optimizations Toward Training Trillion Parameter Models》的论文地址
DeepSpeed的优势如下:
-
支持更大参数量级的模型
-
训练速度更快
-
开销更少
-
代码使用更方便,更改更少
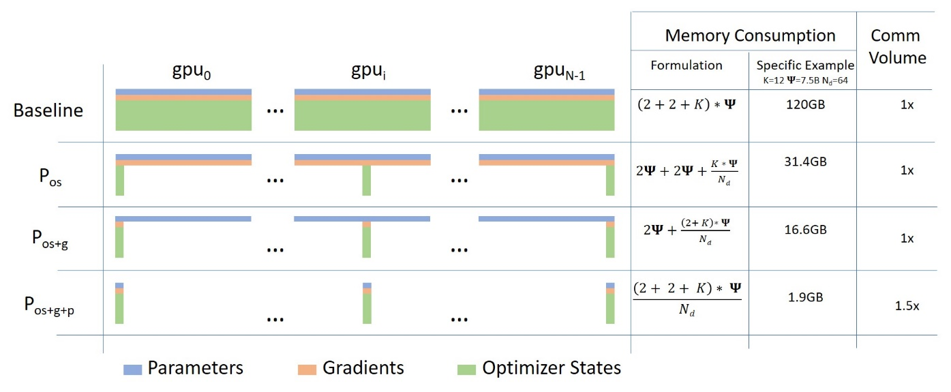
ZeRO的三种主要优化方式:
-
优化器状态拆分:4倍显存使用的减少,不会带来额外的通信时间。
-
优化器状态+梯度拆分:8倍显存使用的减少,这种需要额外的通信时间来同步梯度信息。
-
优化器状态+梯度+模型参数拆分:显存减少的量级随着GPU的个数成正相关(比如有64张卡,那么就会有64倍的显存减少),但这种也会存在最大的通信开销。
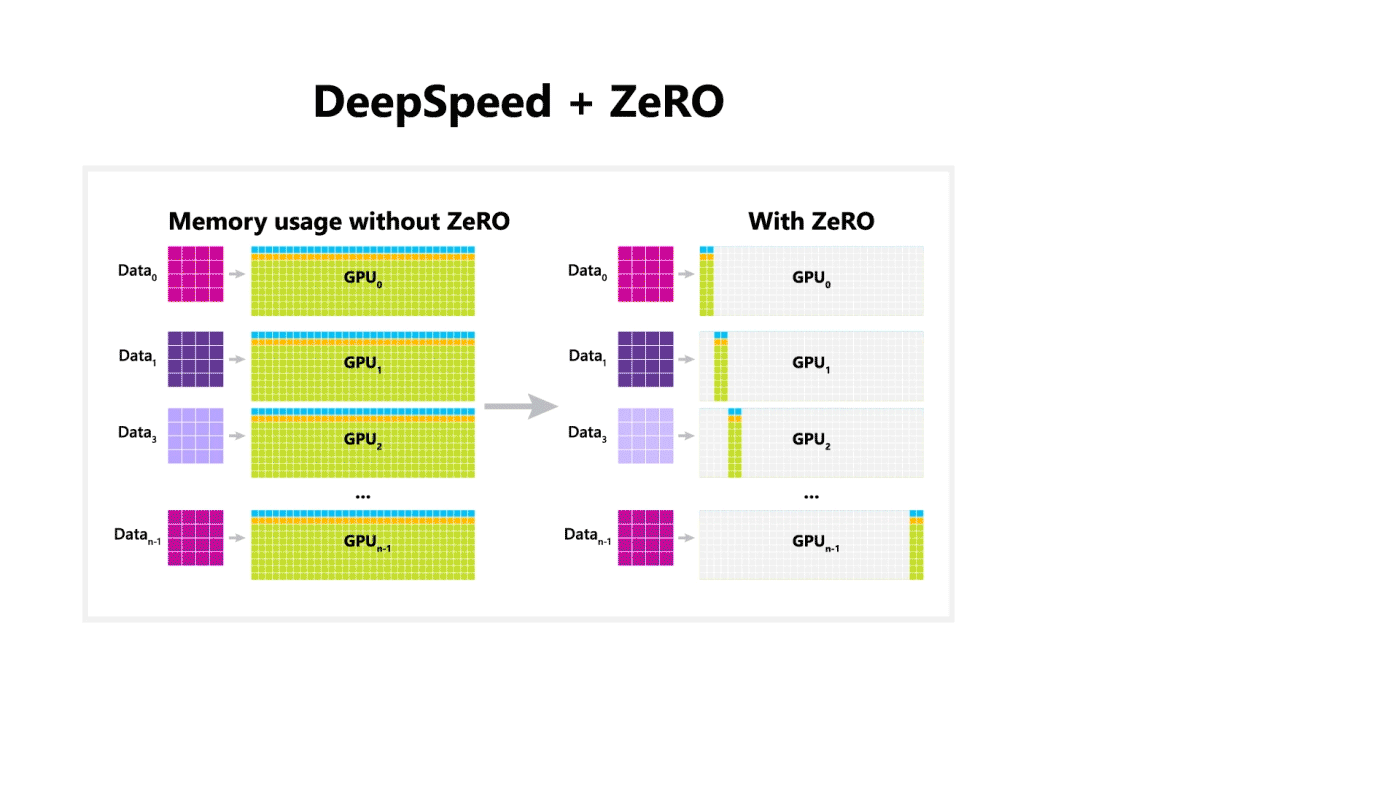
ZeRO第三种方式整体过程:
-
前向传播(蓝色部分)
-
将数据切分为4份 $D_0,D_1,D_2,D_3$,模型切分成4份
-
前向传播时候,对于$D_0$的数据经过$GPU_0$后得到其模型参数$M_0$,然后将模型参数也复制到其他三张GPU上。每张GPU上针对自己的数据都会跑$M_0$的模型参数,一旦$M_0$结束,其他三张GPU删除$M_0$的参数。
-
同上,每份数据和模型都经过上面的流程。前向过程全部结束后,针对每张GPU所代表的每份数据都要计算其loss。
-
-
后向传播(橙色部分)
-
对于$GPU_0,GPU_1,GPU_2$ 而言,在经过各自对应的数据时(这里注意所有的GPU都会存放$GPU_3$的模型参数),会短暂的保持住$M_3$的梯度信息。
-
$GPU_0,GPU_1,GPU_2$ 都会把计算得到的梯度进行累积传递到$GPU_3$上,之后会把模型参数和梯度信息都删除。
-
同上,依次经过$GPU_2,GPU_1,GPU_0$。在梯度累加的过程中,使用优化器的参数进行更新
-
2.3 LLM微调
对于一般的模型进行预训练时,基本都会选择基于预训练模型对下游任务进行微调。但是面对大模型和海量数据,全参数微调明显不现实,所以就需要引入高效的微调方法PEFT(Parameter-Efficient Fine-Tuning)。然后推荐以下几种高效微调技术,都是集成在accelerate中,方便调用。
-
Adapter:Parameter-Efficient Transfer Learning for NLP,是最早发布的参数高效微调技术之一,在 Transformer 架构中添加更多层,并且只对它们进行微调,而不是对整个模型进行微调。
-
LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS,其工作原理是修改神经网络中可更新参数的训练和更新方式。预训练神经网络的权重矩阵是满秩的,这意味着每个权重都是唯一的,不能通过组合其他权重来制作。当将预训练的语言模型调整为新任务时,权重具有较低的“内在维度”。这意味着权重可以用较小的矩阵表示,或者它具有较低的秩。这又意味着在反向传播期间,权重更新矩阵具有较低的秩,因为预训练过程已经捕获了大部分必要的信息,并且在微调期间仅进行特定于任务的调整。
-
Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning,这是第一篇基于仅使用软提示进行微调的想法的论文之一。P-Tuning和Prefix Tuning的思想来自于这篇论文。
-
P-Tuning: GPT Understands, Too,方法旨在优化传递给模型的提示的表示。根据prompt来创建一个小型编码器网络,因此,在使用时候,应该创建一个prompt的提示模版。
-
Prefix Tuning: P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks,P-Tuning的第二版,将可学习参数添加到所有层当中,确保了模型本身能够更多地了解正在对其进行微调的任务。与 P-Tuning 的区别在于,没有完全修改prompt嵌入,而是在Transformer的每一层提示的开头添加很少的可学习参数。它效果很好的一个重要原因是可训练参数的数量不仅限于输入序列。每一层都添加了可学习的参数,使模型更加灵活。