事件抽取实战
一. 事件抽取
1.1 事件抽取定义
在NLP中,我们经常听到NER实体抽取,但是对于事件抽取却相对陌生。这里简单介绍下什么是事件抽取。
- 定义:对非结构化的文本抽取感兴趣的事件信息,并用结构化(论元)进行展示,即事件要素提取。
- 应用:抽取的事件可以广泛应用在舆情发现领域;同时事件抽取其实也是知识图谱的构建中的重要一环。
下面用百度的LIC2021事件抽取任务来举例,事件抽取到底做了什么事?
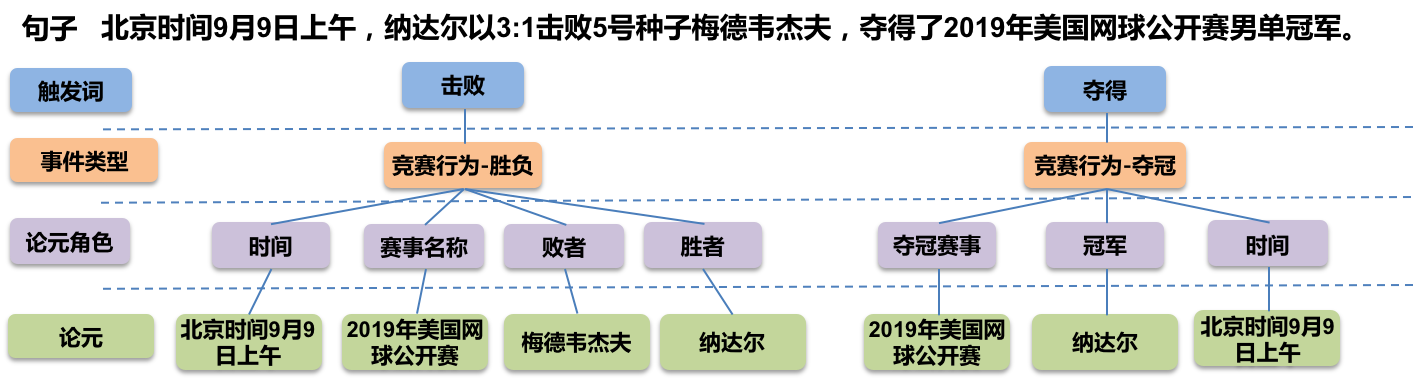
如上图所示,给定了一个句子,通过事件抽取我们可以得到:
- 2个目标事件:竞赛行为-胜负,竞赛行为-夺冠
- 各自事件的论元:比如事件的发生时间/地点,以及胜者、败者、冠军分别是谁。
1.2 事件抽取拆分
通过上面的例子,我们可以看出其实所谓的事件其实就是将论元(实体)、触发词(实体)在文本中抽取出来;同时,也需要将论元和触发词进行关系匹配。因此,我们可以将事件抽取任务进行拆分,即:
- 实体抽取(NER):抽取触发词(动作实体)、抽取论元(名次实体)
- 关系抽取(RE):判定俩俩实体之间是否存在关系(什么类型关系)
二. 相关模型实战
目前,事件抽取模型一般分为pipeline模型(流水线)和联合抽取模型。
- pipeline流水线式模型:先训练一个实体抽取模型,然后再训练一个关系抽取模型,两个模型相互不影响。
- joint联合抽取式模型:将实体抽取和关系抽取放在同一个模型上,这里的loss = 实体抽取loss + 关系抽取loss。
由于BERT的预训练模型在样本较少的情况下,文本特征抽取上有很大优势,因此下面所有实战的模型基本都是基于BERT的。
本人更喜欢torch,因此下面所有实战的代码都是基于pytorch框架的。
2.1 Pipeline模型
我这边使用的方案是:
- NER模型:BERT + BiLSTM + CRF
- RE模型:Enriching Pre-trained Language Model with Entity Information for Relation Classification
2.1.1 NER模型
推荐的git仓库:https://github.com/cooscao/Bert-BiLSTM-CRF-pytorch
NER模型这边选用的文本标注模式为BIOES这种模式,其原因是对比BIO这种标注模式而言,对于实体最尾端的“E”标识能更好的帮助我们在预测时找到实体的尾端,对于错误实体的修正更加有帮助。比如预测的结果为”I-I-I-O-I-I”(BIO)可能识别为2个实体,然是如果是BIOES预测结果为“I-I-I-O-I-E”则其实就是一个实体。
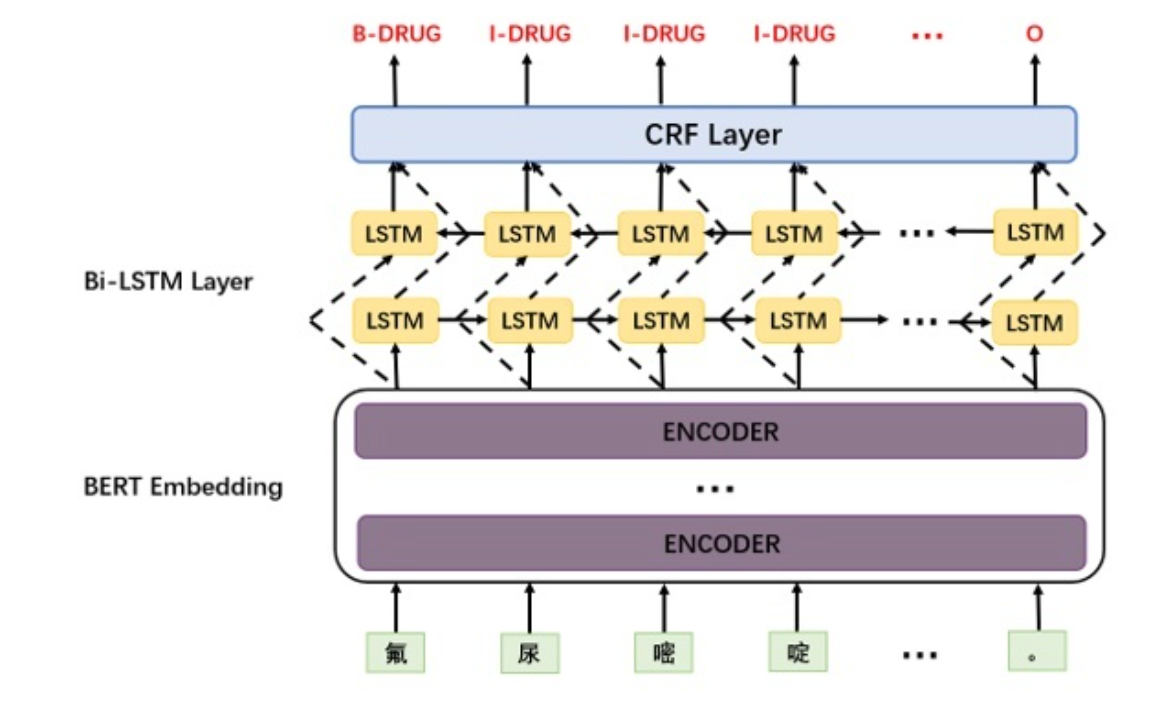
这边主要介绍下选用的层的各自作用:
- BiLSTM层:能解决文本实体的顺序问题,比如抽取的时间中要区分“开始时间”和“结束时间”。
- CRF层:给最终预测的标签添加一些约束来保证预测的标签合法性(其实效果不是很显著)
2.1.2 RE模型
推荐的git仓库:https://github.com/monologg/R-BERT
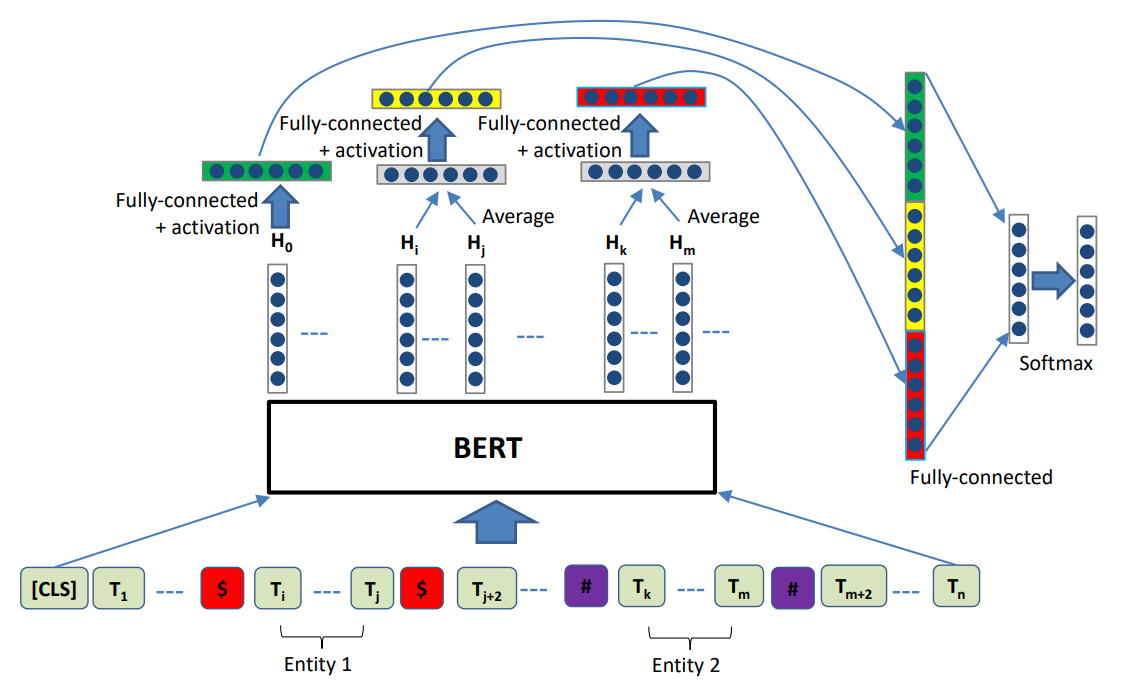
选用该模型的原因:它的模型结构和我起初看的snow ball(雪球算法)很像,在抽取的关系规则上很近似,都是开始词向量 + 实体1 + 中间词向量 + 实体2 + 尾词向量。
这里再推荐一篇基于上面稍加改造的文章(很秀,就加上了“开始词向量” + “中间词向量” + “尾词向量”就能发文章了。。。):基于信息增强BERT的关系分类
模型结构:
- BERT层:文本特征抽取
- 表征关系:将[cls]表征的全句特征 + 实体1的特征 + 实体2的特征
- 分类层:输出关系分类
这里需要说下关于这个关系抽取模型的弊端:当一条文本中包含大量的实体对需要预测其关系时,哪怕是用batch预测,消耗的时间也是很长的。
因此如果真的是用这个模型的话,还是推荐自己改下dataset格式和模型结构,具体可以参考我下面使用的Spert模型结构中的关系抽取部分。
2.2 Joint联合抽取模型
我这边选用的模型是:Span-based Entity and Relation Transformer
原因其实是上面的NER模型用的是BIOES这种数据模式,联合模型我这边就想用span这种标注方式。span最大的优势就是能够解决实体嵌套的问题。比如”武汉长江大桥”这个实体,其实本身是一个“桥”类实体,但是“武汉”两个字也是“市”类的实体,即实体嵌套。
官方的git仓库:https://github.com/lavis-nlp/spert
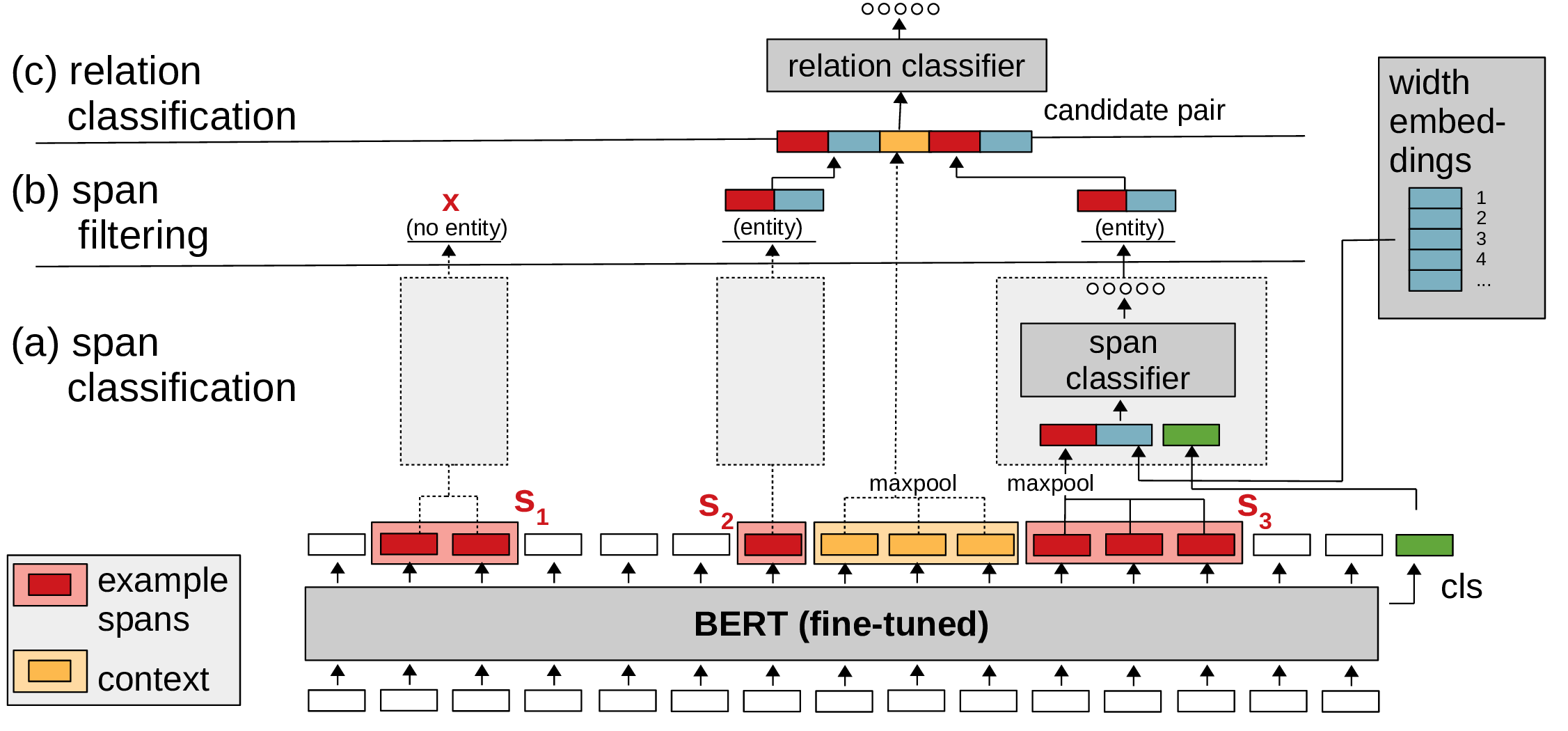
在官方的代码中,模型的训练阶段和推理阶段其实模型结构是不同的:
- 训练阶段:
- 数据加载:创建实体的负样本和关系的负样本。实体的负样本可以理解为图像中的预选框,只不过这里是随机创建并抽样比指定最长实体短些的实体;关系的负样本则是基于俩俩实体是真正实体却没有关联。
- 模型部分:对输入的不同长度的span实体利用嵌入层表示,通过实体的分类器输出实体的logits;在关系分类中,这里是定义了max_pairs作为步长,预选的关系对作为最大长度,滑块的形式来预测关系对,最终将其拼接。
- 推理阶段:
- 数据加载:创建所有的实体候选
- 模型部分:同训练部分 + 实体过滤器(过滤为None的实体)
看了这么多的代码,还是觉得spert作者的这篇repo的代码最棒!
三. 训练的小tricks
- 选用的BERT预训练模型(中文)我这边选用了一大一小两个模型来测试:chinese-roberta-wwm-ext和albert-chinese-tiny。
- 在训练大模型的时候,这里推荐freeze住bert层;而训练小模型的时候,不冻结bert层。
- 在训练的时候发现loss变为nan的时候,在模型和数据都没啥问题的情况下,推荐使用模型剪枝(clip_grad)来处理。
- 设置不同的学习率:在模型的训练阶段对于不同的层我们可能会需要设置不同的学习率,尤其是当我们在预训练模型的基础上对下游任务进行微调,对于预训练模型需要设置较小的学习率,而其他一些我们自定义的层则需要较大的学习率。
- 学习率预热:当设置较大的学习率的时候,会导致模型loss震荡;warm up则可以使得在在最初的几个epoch中lr较小,之后模型趋于稳定后,lr变大到和自己设置的lr一致。