大模型的强化学习微调
一. RT强化学习
1.1 训练过程的演进
- 第一阶段:self-supervised Learning,这里我们可以理解为基座大模型,输入:人工智,输出:慧
- 第二阶段:supervised Learning,这里就是SFT,输入:你是谁?输出:我
- 第三阶段:Reinforcement Learning, 强化学习,输入:世界上最高的山是?输出:喜马拉雅山(而不是输出 我不知道)
1.2 什么是RFT
RFT:reinforcement fine-tuning是强化学习微调。就是在已经预训练好的大模型基础上,用 “奖励机制” 再训练一遍,让模型越来越会做你想要它做的事。
- Fine-tuning:微调,在已经训练好的模型上,用少量数据再训练,让模型更贴合你的任务
- Reinforcement:强化学习,给模型回答的结果进行打分,进行奖励/惩罚
这里使用李宏毅老师的讲解RF的ppt,我们就能很直观的了解RF是什么了
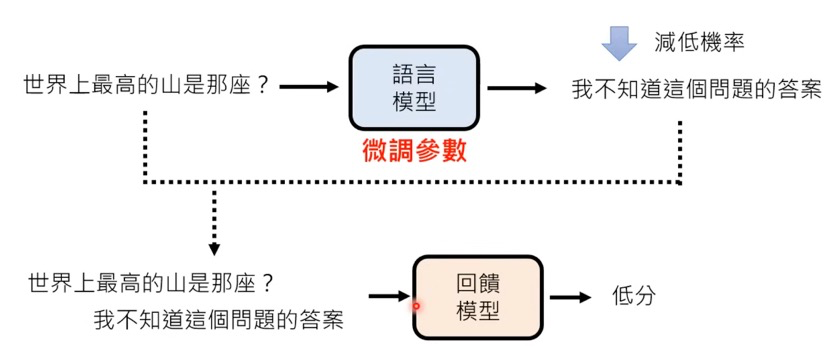
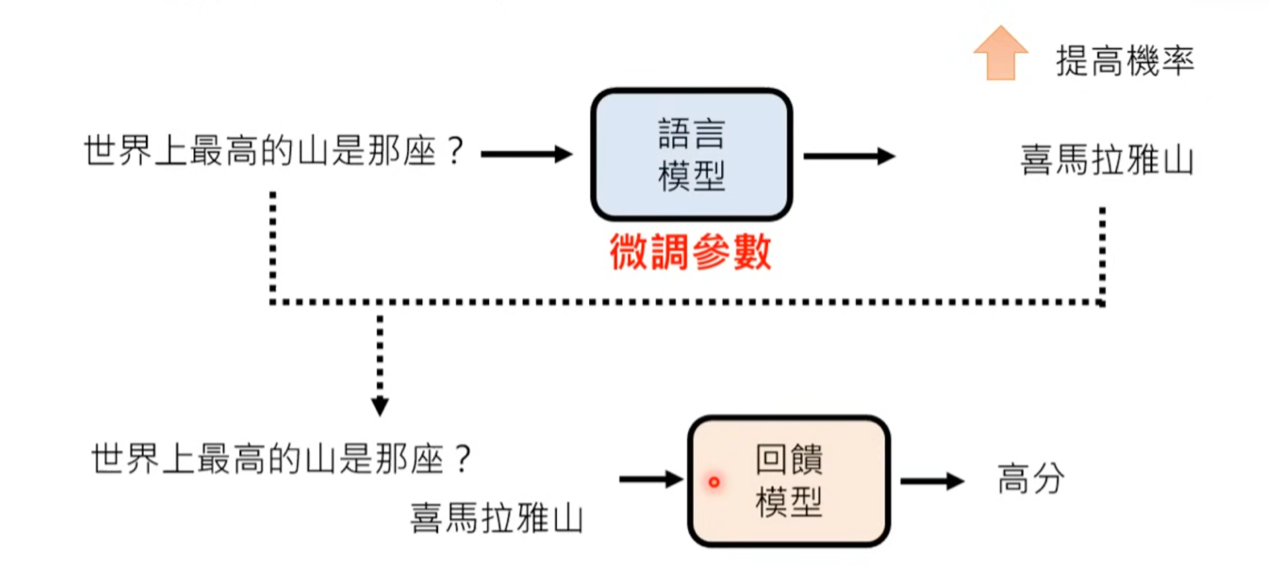
1.3 为什么LLM需要RFT
对于LLM来说,什么样的输出才能算 “好文本”呢:它不仅仅关乎语法或事实,还关乎人类的品味、思路的连贯性、推理的正确性、消除输出中不必要的偏见等等。
因此我们需要强化学习来帮忙LLM来适应 符合人类的偏好:
- 人类来评判LLM,而非公式:人类成为我们的“奖励函数”。
- 学习人类的喜好:我们训练 LLM 生成人类更可能喜欢的文本。
1.4 RFT和SFT的对比
| RFT | SFT | |
|---|---|---|
| 训练量级 | 少于100 | 10w以上 |
| 训练时间 | 更快 | 漫长 |
| 模型学习 | 基于正反case进行迭代 | 对于输入和输出的关联进行记忆 |
| 类比 | 教会了AI如何去思考+行为 | 用信息数据填充AI的脑子里面 |
1.5 什么场景适用于RFT
- 没有标签数据:可以通过自己定义的验证代码来判别输出结果的正确性
- 只有少量的标签数据:没有足够的量级支持SFT
- 需要COT来提升模型表现:RFT能让COT的过程控制变短,从而提升模型推理速度
- 需要多个步骤的逻辑推理:当需要模型需要一步一步进行决策的时候,而不是简单的直接映射关系,RFT更适合
- 更快速的进行模型的迭代:以更快的速度,更短时间进行模型的实时迭代
1.6 Function Call中RF的应用
如果大家在项目中经常使用function call或者需要将大模型输出的结果进行二次解析的话,经常就会遇到一个很蛋疼的问题,那就是 明明提示词写的就是让LLM输出 指定的json结构的返回结果,但是往往 LLM 最终输出的都是非结构化的数据。
因此我们可以利用RF对模型进行训练,专门强化输出结构化的推理结果。
二. RT的演进
2.1 奖励模型
为什么需要奖励模型?
我们不能让人类在LLM的训练过程中对每个次训练迭代的输出结果进行评判,那样会太慢了,因此我们需要训练一个奖励模型——一个学习模仿人类偏好的AI评判模型:
- 奖励模型 = AI 口味测试员:我们使用人类偏好数据对其进行训练。它会学习给人类倾向于喜欢的文本赋予更高的分数。
- 强化学习算法使用奖励模型:诸如 PPO、DPO 和 GRPO 之类的算法使用这种奖励模型来指导语言学习模型 (LLM) 的学习。LLM 尝试生成能够获得 AI 评委高分的文本。
2.2 PPO
PPO论文:https://arxiv.org/abs/1707.06347
InstructGPT论文:https://arxiv.org/abs/2203.02155
这个是OpenAI在17年提出的近端策略优化 (PPO),到22年OpenAI提出了InstructGPT之后,将 PPO 提升到了一个全新的高度。这篇论文展示了如何利用 PPO 根据人类偏好来微调大规模语言模型(例如 GPT-3)。InstructGPT 不再仅仅是预测下一个词,而是学会了生成人类真正喜欢的文本——既有帮助又无害的文本。
以下是PPO训练的步骤:
- 生成文本:LLM通过不同提示词来生成推理的文本
- 奖励模型对生成的文本进行评分。
- 利用广义优势估计 (GAE)来计算优势:它会考虑多个词的奖励,平衡方差(MC)和偏差(TD)之间的权衡。这就像不仅在最后给予奖励,而且在过程中也会对表现良好的“小步骤”给予奖励,能计算每个词选择的提升幅度。
- KL散度的惩罚:新旧结果的差异很大,会施加惩罚,从而增强稳定性。
- 更新价值函数:训练价值函数,使其准确地预测不同文本生成的“好坏”。
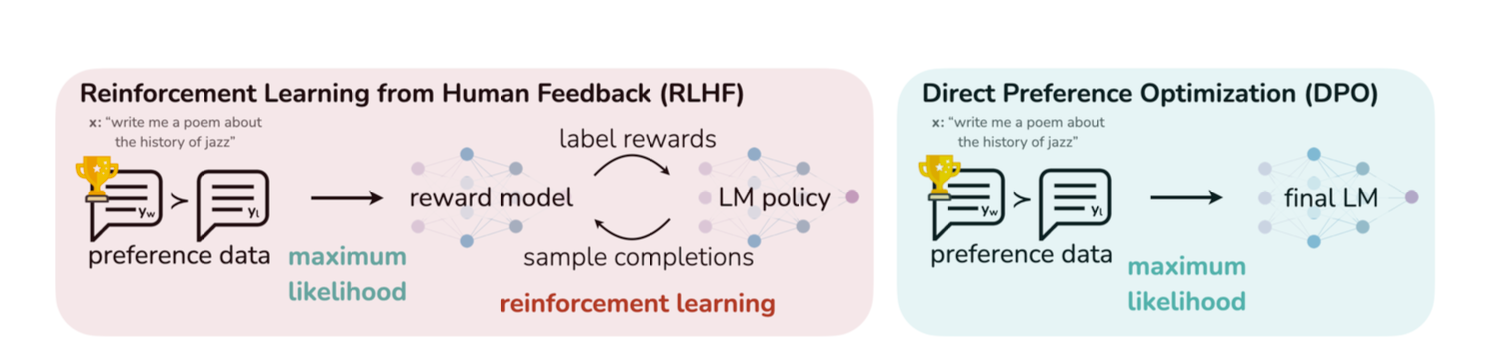
2.3 DPO
DPO论文地址:https://arxiv.org/abs/2305.18290
这是斯坦福大学在24年7月发布的直接偏好优化 Direct Preference Optimization(DPO):
- 直接:DPO 就像直接告诉 LLM:“ A 比 B 好。多像 A,少像 B!”它省去了策略更新步骤中的中间环节(强化学习中用于策略优化的奖励模型)。
- 不需要迭代循环:利用类似分类的损失——直接使用logits损失函数,该函数直接比较两个模型的概率 ,直接基于人类偏好数据优化 LLM
2.4 GRPO
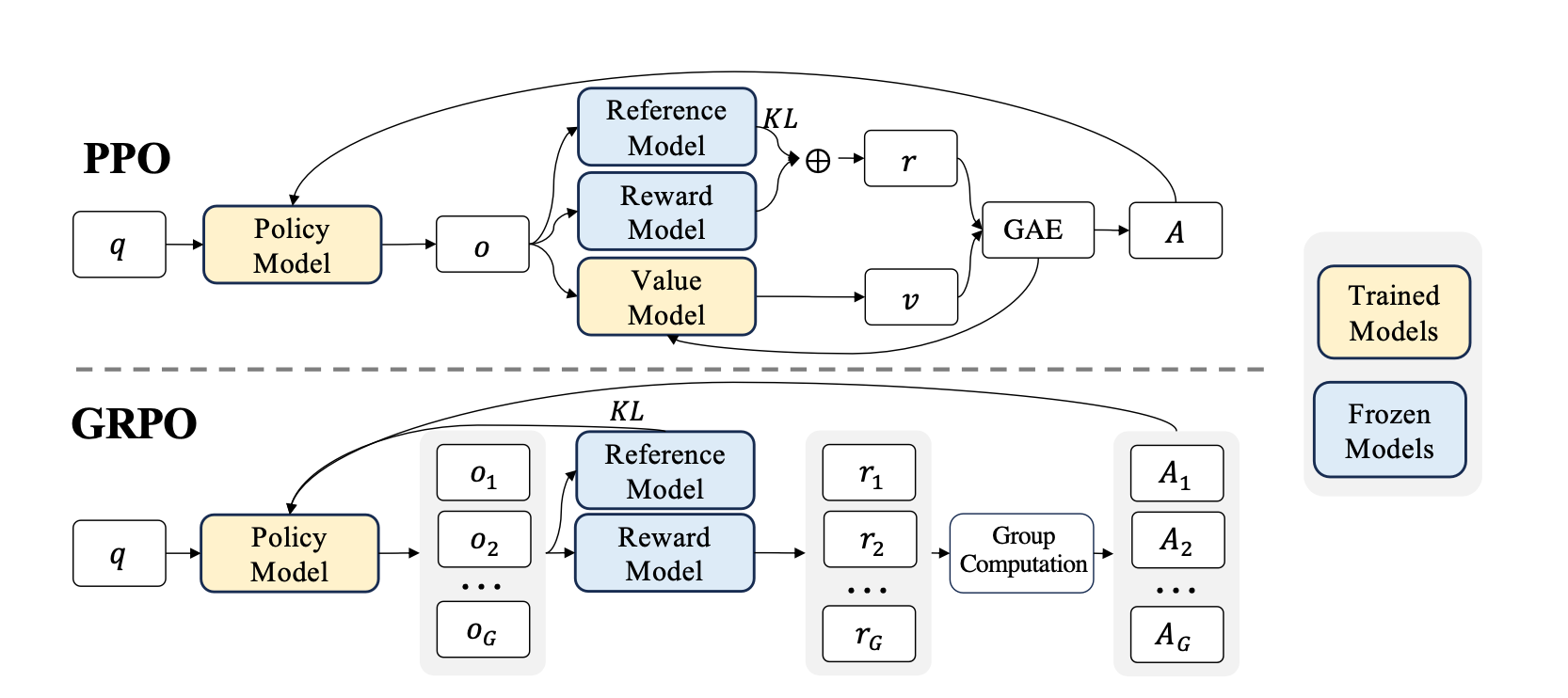
GRPO论文:https://arxiv.org/pdf/2402.03300
这个是DeepSeek在24年8月发布的强化学习的方式:Group Relative Policy Optimization(GRPO)。GRPO基于PPO,旨在简化RLHF训练流程,使其速度更快,尤其适用于复杂的推理任务。
- 去掉了PPO的Value Model:更加轻量高效
- 核心Group Relative Policy Optimization:不再通过分组分数来估算基线,从而显著减少训练资源消耗。使用一组由 LLM 生成的针对同一提示的回答,来评估每个回答相对于组内其他回答的“优劣” 。
三. 基于GSM8K数据集的GRPO的实操
3.1 数据准备
这里用推荐的GSM8K数学问答的数据集
from datasets import load_dataset
def extract_hash_answer(text):
"""Extract numerical answer from GSM8K format (#### marker)"""
if "####" not in text:
return None
return text.split("####")[1].strip()
def process_dataset_example(example):
"""Convert GSM8K example to conversation format for GRPO training"""
question = example["question"]
answer = extract_hash_answer(example["answer"])
prompt = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": question},
]
return {
"prompt": prompt, # Input conversation
"answer": answer, # Ground truth for reward functions
}
def load():
dataset = load_dataset("openai/gsm8k", "main", split="train")
# Apply conversation formatting to all examples
dataset = dataset.map(process_dataset_example)
return dataset
3.2 定义奖励机制
实施四种互补的奖励函数来评估数学推理的不同方面:
- 格式完全匹配:结构完全一致
- 近似匹配:格式元素部分得分
- 答案正确性:数学准确性,分级评分
- 数字提取:解析和输出数值结果的能力
这里举其中第一个例子
def match_format_exactly(completions, **kwargs):
"""
完美遵守格式可获得高额奖励(3.0)
确保模型学习完整的结构化输出模式
"""
scores = []
for completion in completions:
response = completion[0]["content"]
# Check if response matches complete format pattern
score = 3.0 if match_format.search(response) is not None else 0.0
scores.append(score)
return scores
3.3 训练
训练过程其实和sft很类似,都是基于lora进行训练,但是唯一差别就是定义了reward function
# Configure GRPO training parameters for mathematical reasoning
training_args = GRPOConfig(
learning_rate=5e-6,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
max_prompt_length=1024,
max_completion_length=1024,
max_steps=10,
logging_steps=1,
output_dir="./trl_grpo_outputs",
max_grad_norm=0.1,
)
trainer = GRPOTrainer(
model=model,
reward_funcs=[
match_format_exactly,
],
args=training_args,
train_dataset=dataset,
)
至此,训练的过程就结束啦!