大模型基于检索增强的微调-RAFT
一. RAFT简单介绍
论文:《RAFT: Adapting Language Model to Domain Specific RAG》
1.1 RAFT的优势
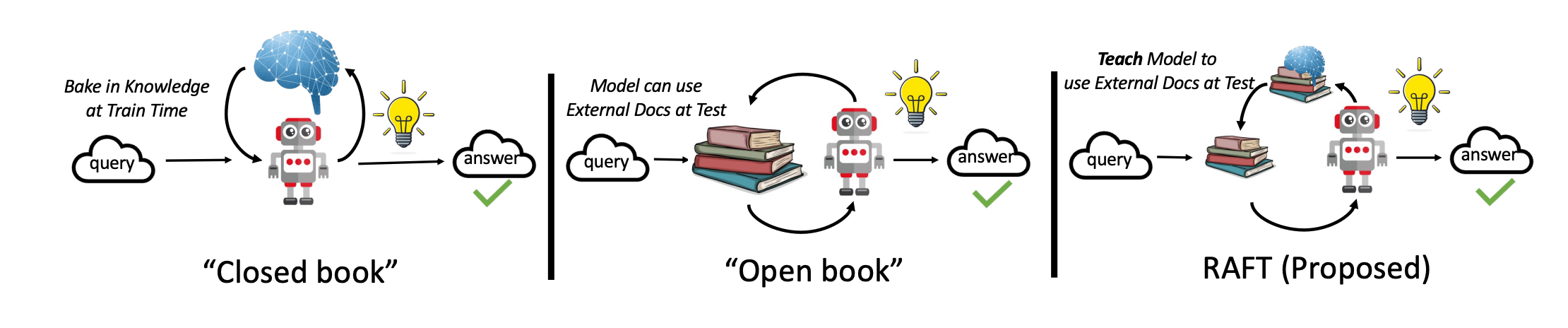
RAFT其实是基于RAG(检索增强)的SFT(有监督微调),那么他和这两者的差异是什么呢?
- RAG:检索增强是基于提出的问题在向量数据库中检索相应的片段,然后作为线索合并问题喂给大模型,然后输出。然后这里会出现一个问题:模型对于特定领域的知识没有得到提前学习的机会,说白了就是给了大模型很多材料,但是无法非常有效的使用这些材料。
- SFT:有监督微调是基于提供特定的QA对的方式来喂给大模型,然后能够让大模型额外扩充知识面的方式。但是这也会存在一个问题:这些QA对更多的是让大模型增加了额外文档的记忆,而忽略了在回答实际问题时使用文档的机会,要么没有正确处理在寻找合适的文档来学习时出现的错误。
- RAFT:基于检索增强的微调则是结合RAG+SFT提出的一种新的微调方案。他的优势:
- 过微调确保模型在特定领域的知识上得到良好的记忆和训练,从而达到对不准确的检索文档进行发现。
- 通过训练模型来将“理解问题”、“检索知识”和“正确答案”进行关联,从而提高达模型回答的准确性。
这也就是整片文章中一致强调的RAFT其实是一种“开卷考试” + “特定领域的提前学习”。
1.2 RAFT如何训练
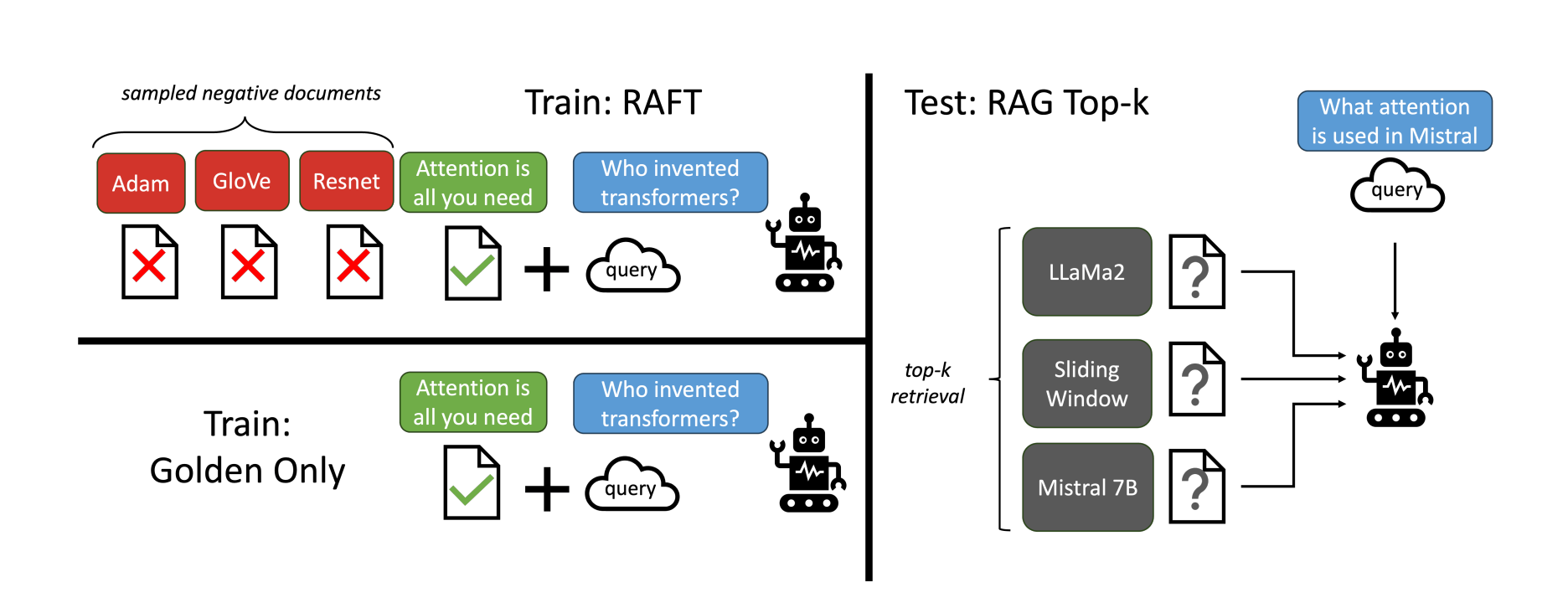
区别于常规的SFT,RAFT在训练中加入了干扰的文档 + 正确的文档让模型来学习。这使得模型学习到的是基于记忆和文档的混合判断,参考论文中的“which is a mixture of both memorization and reading”。
- 训练的内容分为2块:
- 找到核心依据:QA对 + 标准答案的文档 + 多个误导的文档 + 思维链
- 正确的例子:QA对 + 标准答案的文档 + 思维链
- 训练的核心:通过思维链来解释找到的答案,从而基于上下文信息,思考其答案,并链接到相关文档。
二. 基于unsloth和lamma_index来实现FAFT
2.1 基于ollama和lamma_index来构建数据集
RAFT的数据集的特点是:
- QA对
- 正确文档
- 错误文档
- 思维链
所以我们需要一个能够提供思维链的大模型,帮助我们生成上述这些内容。
- 模型:Qwen3-32B,选择这个千问模型是因为中文很友好+支持思维链+阿里的预训练的数据很顶
- 调用框架:ollama,调用比如openai需要花钱,这个本地部署,调用不花钱!
2.2 安装相关依赖
这里需要使用以下几个深度学习相关的框架:
- lamma_index: 和langchain感觉很像,只是这个更加偏重于增强大型语言模型 (LLM) 处理广泛和异构数据集的能力。当然也能帮助我们构建raft数据集咯。
- unsloth: 大模型训练的框架
依赖:
llama_index
llama-index-packs-raft-dataset
llama-index-llms-ollama
llama-index-embeddings-ollama
llama-index-packs-rag-evaluator
unsloth
2.3 构建raft数据集
我这边选择了法律相关的文书作为文档,然后结合lamma_index来向大模型提问,进而生成训练所需的问题和答案以及思维链。
import os
import datasets
import pandas as pd
from llama_index.packs.raft_dataset import RAFTDatasetPack
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
def gen_qa_raft_dataset():
llm = Ollama(model="qwen3:32b", request_timeout=60.0)
embed_model = OllamaEmbedding(model_name="modelscope.cn/yingda/gte-Qwen2-1.5B-instruct-GGUF:latest")
sub_dir = 'data/laws/'
df_list = []
for file_path in os.listdir(sub_dir):
print(file_path)
file_path = os.path.join(sub_dir, file_path)
raft_dataset = RAFTDatasetPack(file_path,
llm=llm,
embed_model=embed_model,
num_questions_per_chunk=3,
num_distract_docs=3,
chunk_size=2048)
dataset = raft_dataset.run()
df = dataset.to_pandas()
df['messages'] = df.apply(lambda row: [{'content': row['instruction'], 'role': 'user'},
{'content': row['cot_answer'], 'role': 'assistant'}], axis=1)
df_list.append(df)
df_all = pd.concat(df_list)
dataset = datasets.Dataset.from_pandas(df_all)
dataset.to_csv("data/法律文书_raft_dataset.csv", encoding='utf-8')
然后我们可以打开看下结果,会发现包含了一下列:
- question:大模型生成的问题
- context:多个文档(这里就是raft中的正确文档+误导文档)
- cot_answer: 思维链答案
- instruction: 多个文档 + 问题
- message: 完整的基于rag的问答对
2.4 基于lora的sft
- 加载上述存储的dataset
df = pd.read_csv("data/法律文书_raft_dataset.csv", index_col=False) dataset = datasets.Dataset.from_pandas(df) - 构建dataset的template
tokenizer.chat_template = DEFAULT_CHAT_TEMPLATE
SYSTEM_PROMPT = """你是一位很有能力的问题解答者,能够根据问题和相关背景提供答案。"""
def apply_chat_template(example, tokenizer):
messages = example["messages"]
messages = messages.replace('\n',',')
messages = eval(messages)
# We add an empty system message if there is none
if messages[0]["role"] != "assistant":
messages.insert(0, {"role": "system", "content": SYSTEM_PROMPT})
example["text"] = tokenizer.apply_chat_template(messages, tokenize=False)
return example
column_names = list(dataset.features)
raw_datasets = dataset.map(apply_chat_template,
num_proc=cpu_count(),
fn_kwargs={"tokenizer": tokenizer},
remove_columns=column_names,
desc="Applying chat template",)
raw_datasets = raw_datasets.train_test_split(test_size=0.1)
# create the splits
train_dataset = raw_datasets["train"]
eval_dataset = raw_datasets["test"]
- 加载模型
# 加载模型 - 使用Unsloth的FastLanguageModel加载预训练的Qwen3-8B模型
model, tokenizer = FastLanguageModel.from_pretrained(
model_name='Qwen/Qwen3-0.6B', # 模型路径
dtype=torch.float16, # 使用float16数据类型以减少内存占用
max_seq_length=2048, # 设置最大序列长度为2048
load_in_4bit=False # 使用4位量化加载模型,进一步减少显存占用
)
model = FastLanguageModel.get_peft_model(
model,
r = 32, # Choose any number > 0! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 32, # Best to choose alpha = rank or rank*2
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
- 训练
trainer = SFTTrainer(
model = model,
train_dataset = train_dataset,
eval_dataset = eval_dataset,
args = SFTConfig(
dataset_text_field = "text",
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4, # Use GA to mimic batch size!
warmup_steps = 5,
# num_train_epochs = 1, # Set this for 1 full training run.
max_steps = 30,
learning_rate = 2e-4, # Reduce to 2e-5 for long training runs
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
report_to = "none", # Use this for WandB etc
),
)
tokenizer.pad_token = tokenizer.eos_token
train_result = trainer.train()
三. RAFT的总结
RAFT和一般的SFT而言,其实本质上没有任何差别,只是说将RAG融合进了有监督微调中,从而达到一种让模型拥有更加准确筛选文档+使用特定领域类文档的能力。而在训练中增加误导的文档,更是能让模型达到一种思考和过滤无关信息的能力。